Automated Regression Testing of the Browser Core
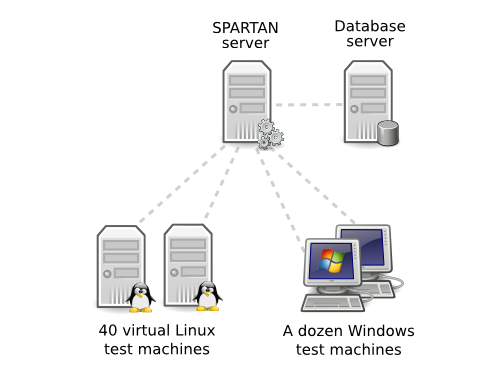
The cornerstone of all testing done on the core of the Opera browser is our automated regression testing system, named SPARTAN. The system consists of a central server and about 50 test machines running our 120 000 automated tests on all core reference builds. The purpose of this system is to help us discover any new bugs we introduce as early as possible, so that we can fix them before they cause any trouble for our users.
Step one: Preparing a build
Before SPARTAN can test anything, it will require a build to test. Our build system automatically creates builds every night and pings SPARTAN when they are ready. Developers and testers can also request their own builds from the build system, using any build tag they want, to test stuff from their own experimental branches before this is eventually merged into the stable mainline we base our products on.
Unlike other browser vendors we ship our browser on a variety of different platforms. So our core build packages do not contain just one binary, but several. One for each general product category. Each of these profiles have the same feature set and memory constraints as the platform they correspond to. The whole set of tests are run on each of these profiles.
Step two: Testing
When the SPARTAN server is informed about the existence of a new build it will add this build to its testing queue and distribute a few hundred tests to each of the test machines the next time they ask for more work. Each test machine works independently with its assigned tests. It will download the Opera binaries it has been told to use, and run its assigned tests on it. Once it has finished its batch of tests, it will pass the test results back to the SPARTAN server, and again ask what to do next.
If it ever runs out of new builds to test, for example during the weekend, it will look back at older builds and run any newly added tests on them too. This to ensure that we have a full history for each test, and at any time can determine when a fix or regression was first introduced without having to manually test things again.
We have several different types of tests:
- Unit tests
- Unit tests (or selftests), written by the same developers who write the running code, tests individual functions and APIs.
- JavaScript tests
- Our JavaScript tests test a wide array of different features on a functional level. This includes for example tests for the Selectors API, tests for common JavaScript frameworks, or any other feature we can interact with through JavaScript.
- Watir tests
- Many tests require some sort of user interaction. To test forms, for example, one must click buttons or checkboxes or type in text fields. To avoid having to do this manually, we have implemented support for the cross-browser Watir API. While others use this API to test their web applications, we use it to test the browser itself.
- Visual tests
- To test our stylesheet and graphics code, we need to test that our visual test cases look right. Some of our visual tests automatically compare two pages or two elements to determine whether they are the same. On other tests, the test machines will take a screenshot of the rendered page and pass it back to the SPARTAN server. If the SPARTAN server has seen this screenshot before, it will know whether that particular rendering means PASS or FAIL. If SPARTAN has never seen it before, the screenshot must be labeled as PASS or FAIL by a human. This is labour-intensive work we intend to further reduce through reftests.
- Performance tests
- A modern browser must not only pass tests for all its different features. It must also be fast. SPARTAN runs a number of different performance tests, both internally and externally developed, on our builds. If Opera becomes slower at any particular test, this will be flagged as a regression.
- Crash tests
- We create test cases for every single bug we analyze and fix, and SPARTAN runs most of these. Among our bug-based test cases are crash tests. If Opera can load these tests without crashing, the test has passed. If it crashes, we have reintroduced an old crash, and must fix it.
All in all, we currently run about 120 000 tests on each configuration in each build, but this number changes daily. We continuously write new test cases for bugs or test suites for new or old features, and we also copy any publicly available test suites we find useful. Right now we are also working on automating many of our previously manual tests, including memory tests.
Step three: Human intervention
Once the machines are done with their part of the job with any particular build, they will send an email to a human who will continue the work. SPARTAN will generate a report of changes between this build and the previous build. In most builds there are some tests that go from FAIL to PASS because we have fixed something. But there are also often regressions—tests that go from PASS to FAIL—because we accidentally broke something while fixing something else. This is expected, and is the reason for why we do regression testing. We know there will always be regressions, and need to find them as quickly as possible in order to fix them before they can cause any trouble for users or customers.
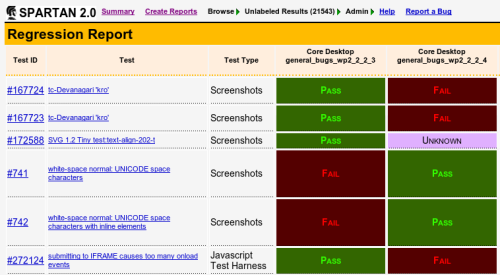
The human tester will analyze each regressed test. If a hundred different tests started failing at the same time, they could all have broke because of one regression, or there could be several different ones. For each unique regression identified the human tester will report a new bug and assign it to the developer responsible for the code that broke. Once a fix is ready, we will run all our tests again.
